Prompt: If 1 is to 7, 9 is to 63, and 4 is to 28, then what about 6?
AI's response: 6 is to 42.
This exchange demonstrates one of the most striking capabilities of modern large language models (LLMs): in-context learning (ICL). The model was never trained explicitly on this multiplication task ("multiply by 7"). It just looked at the examples in the prompt, inferred the pattern, and applied it to the new prompt. This was done all within the forward pass.
ICL is the umbrella term for this kind of inference-time adaptation, where a model changes behavior based on examples or instructions in the prompt, without any weight updates. Traditionally, this adaptation, or "learning", is an offline process: you train a model on data, weights update via gradient descent, and the result is a model with new capabilities baked in. In ICL, the weights don't change, but something in the forward pass is doing work that resembles learning.
Almost every interesting capability of modern LLMs depends on ICL in some way. Prompt engineering leverages ICL. Few-shot prompting is ICL. Even more advanced behaviors like multi-step reasoning or agentic workflows are built on top of the model's ability to use context to learn and specialize its behavior at inference time.
This foundational capability is also mysterious. What is the model learning during the forward pass that lets it solve a problem instance it has never seen before? The field has partial answers but is far from a complete picture. ICL was prominently demonstrated in the GPT-3 paper (Brown et al., 2020) and characterized behaviorally in synthetic settings shortly after (Akyürek et al., 2022; Garg et al., 2022). At the mechanistic level, induction heads have been identified as a foundational circuit (Olsson et al., 2022). On the theoretical side, recent work has shown that one-layer linear self-attention can be analyzed as implementing gradient descent (von Oswald et al., 2023; Ahn et al., 2023; Mahankali et al., 2024) and softmax attention has been connected to kernel regression (Collins et al., 2024; Cheng et al., 2025) in restricted settings. More recent empirical work has begun to study ICL mechanistically in real models, including Anthropic's circuit-tracing analyses (Lindsey et al., 2025). So while ICL is well-understood behaviorally and theory is making progress in restricted settings, much remains open at the mechanistic level for trained multi-layer transformers. This blog, on a small scale, makes mechanistic contributions to our understanding of ICL.
A common approach is to study a simplified version of the problem. In this blog, I conduct a mechanistic analysis of ICL in a synthetic linear regression setting inspired by Garg et al. (2022), who introduced a clean, controlled task where small transformers learn to do linear regression in their forward pass. The setting is small enough to fully reverse-engineer, but rich enough to capture something real about ICL. The hope is that what we learn here gives us a foundation for understanding ICL in larger, more capable models.
Let's start by understanding this setting informally. Every time we prompt the model, it sees a fresh dataset of 20 $(x_i, y_i)$ pairs and a query $x_q$, and must predict $y_q$. The pairs are generated from a random linear function $y = w^\top x$, where $w$ is sampled fresh each time. Because $w$ is different on every prompt, the model can't memorize any particular $w$. It has to learn a general procedure for solving linear regression from the examples in the prompt, and then execute that procedure in its forward pass to predict $y_q$ accurately.
Because linear regression has a known optimal solution, we can reverse-engineer the model and ask "what is actually happening?" and compare to a known ground truth.
Experimental Setup
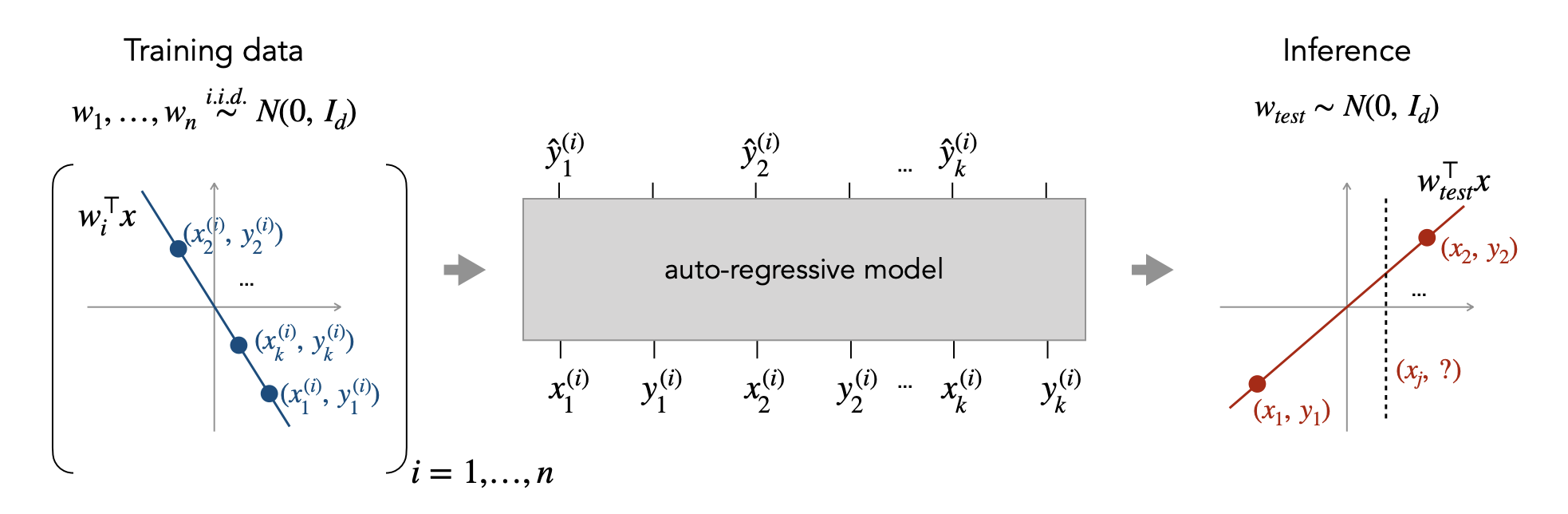
I adopt an in-context linear regression task inspired by Garg et al. (2022), with smaller scale to enable mechanistic analysis. This setting has been widely used: Akyürek et al. (2022), von Oswald et al. (2023), Ahn et al. (2023), Raventós et al. (2023), Panwar et al. (2024), Collins et al. (2024), and Hill et al. (2025), among others.
Task. At each training step, I sample a fresh weight vector $w \sim \mathcal{N}(0, I_d / d)$ with $d = 5$, defining a linear function $y = w^\top x$. I then sample $n = 20$ in-context inputs $x_i \sim \mathcal{N}(0, I_d)$ and compute their labels $y_i = w^\top x_i$. A separate query $x_q \sim \mathcal{N}(0, I_d)$ is sampled, and the model is supervised to predict $y_q = w^\top x_q$. The input is a flat sequence of $2n + 1 = 41$ tokens: $[x_1, y_1, x_2, y_2, \ldots, x_{20}, y_{20}, x_q]$. The weight $w$ is hidden from the model at all times. Because $w$ is resampled every step, the model cannot memorize any specific $w$ and must instead learn a general procedure for solving linear regression from the in-context examples. The default setting uses $n/d = 4$; I vary this ratio in later experiments.
Model. Standard decoder-only transformer blocks with pre-norm layernorm, 4 attention heads, hidden dimension $d_\text{model} = 128$, feedforward dimension $d_\text{ff} = 256$, GELU activations, and learned positional embeddings. Each $x_i$ is embedded into the residual stream via a linear projection from $\mathbb{R}^d \to \mathbb{R}^{d_\text{model}}$; each $y_i$ is placed as a scalar in the first coordinate of its token position and embedded through the same input projection. The final $y_q$ prediction is read from a linear projection applied to the residual stream at the $x_q$ position after the final layer. Depth (number of transformer blocks) varies across experiments and is the main variable under study. I train models at depths 1, 2, 3, 4, 5, 6, and 8.
Training. MSE loss on $y_q$. Adam optimizer with learning rate $3 \times 10^{-4}$ and a OneCycleLR schedule (pct_start = 0.1), batch size 256, trained for 200k steps unless otherwise noted. The extended-training analysis in Part 2 runs to 400k–800k steps. The primary seed for all Part 1 analyses is 42. Cross-seed replications use seeds 100 and 200. The 3L extended-training analysis additionally uses seeds 500 and 600.
Evaluation. By default, evaluation inputs are drawn from the same $\mathcal{N}(0, I_d)$ distribution as training. The out-of-distribution stress tests sweep alternative covariance structures for the in-context inputs $x_i$: diagonal anisotropic (condition number 100), strongly diagonal (condition number 10,000), and correlated non-diagonal. The weight $w$ is always drawn from the same training prior.
Part 0: The one-layer transformer
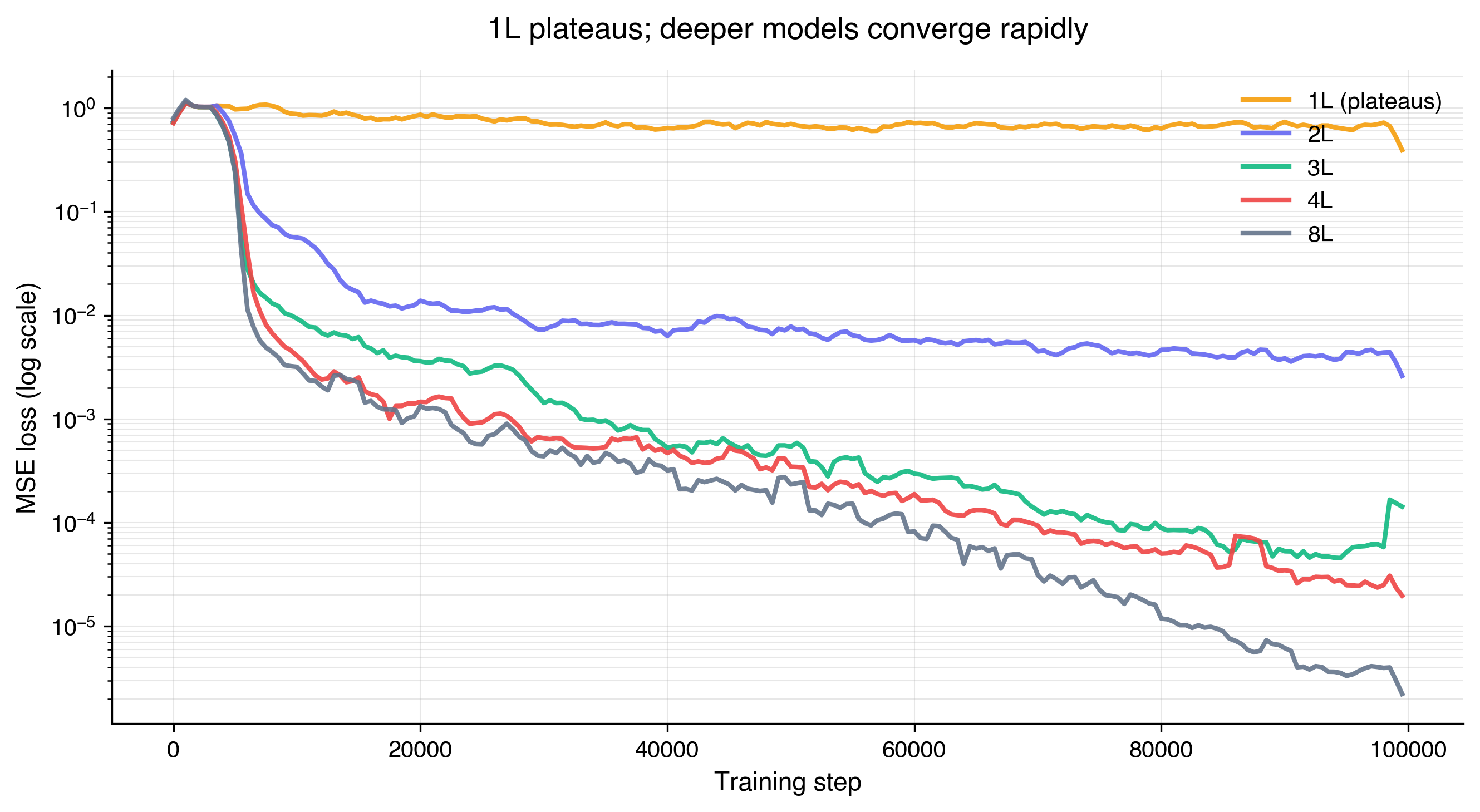
Just to get a baseline, we train models at various depths and plot the MSE loss. As we can see, relative to other models, the 1L transformer plateaus quickly and never improves. In a later section, we will provide an explanation about why the 1L model is insufficient for the model to learn linear regression in this ICL setting. But with this result established, we will proceed with the analysis of deeper models.
Part 1: Reverse-engineering the two-layer transformer
The 2L transformer was the minimal depth that learned ICL linear regression in our setting. Prior work has characterized the 2L transformer behaviorally, with partial mechanistic explanations for what's happening internally. In this section, I extend this with deeper mechanistic analysis where possible. Ultimately, we will see that the 2L transformer contains partial representations of ridge regression, but takes a training distribution shortcut localized at L1 MLP.
Behavioral baseline
Prior work from Akyürek et al. (2022) established that shallow transformer models behave like ridge regression. By "behave", I mean in a black-box sense: given the same inputs, the model's outputs roughly match the ridge regression solution's outputs. It can be shown that 2-layer transformers matched a ridge regressor at a specific $\lambda$, and that the best-match $\lambda$ shifted with added label noise in the way ridge regression predicts. This is a behavioral signature consistent with the model implementing something ridge-like.
The behavioral analysis serves as a valuable baseline. However, just because something behaves like something else, doesn't mean their internals are the same. We will pursue this hypothesis further at an algorithmic level. That is, given that our model seems to behave like ridge regression, can we find sufficient evidence to claim that it is indeed executing ridge regression algorithmically? By "algorithmic" level, we mean that our model is actually executing the same steps as ridge regression would. If we can find sufficient evidence that our model is executing ridge regression's steps algorithmically, we can be more confident in the claim that our model has re-discovered the ridge regression algorithm. This would indeed be interesting, as it would mean that this algorithm is somehow encoded into the weights, and used to accurately make predictions on novel inputs in its forward pass.
Linear probing
To further investigate our hypothesis, we test if any of ridge regression's quantities are "present" within the model's computation. In other words, we introspect the model's sub-layers to see if we can find evidence that it contains representations of ridge regression.
Recall that the closed-form solution for ridge regression is:
$$w = (X^TX + \lambda I)^{-1}X^Ty$$
Some reasonable quantities of ridge regression to look for are $X^TX$, $X^Ty$, and $w$. In order to test if these quantities are "present" at some point internally in the model, we adopt a standard methodology known as linear probing, first proposed by Alain & Bengio (2016).
The intuition behind linear probing is that we test to see if there exists a linear mapping from the per-layer activations to the target quantity. If the probe's prediction aligns strongly with the target quantity, then this means that the quantity is easily accessible to the model in the sense that it is only one linear mapping away from being retrieved.
Here are the results of this linear probing. I denote the two layers of our 2L transformer model as L0 and L1, along with probing results at sub-layer attention and MLP.
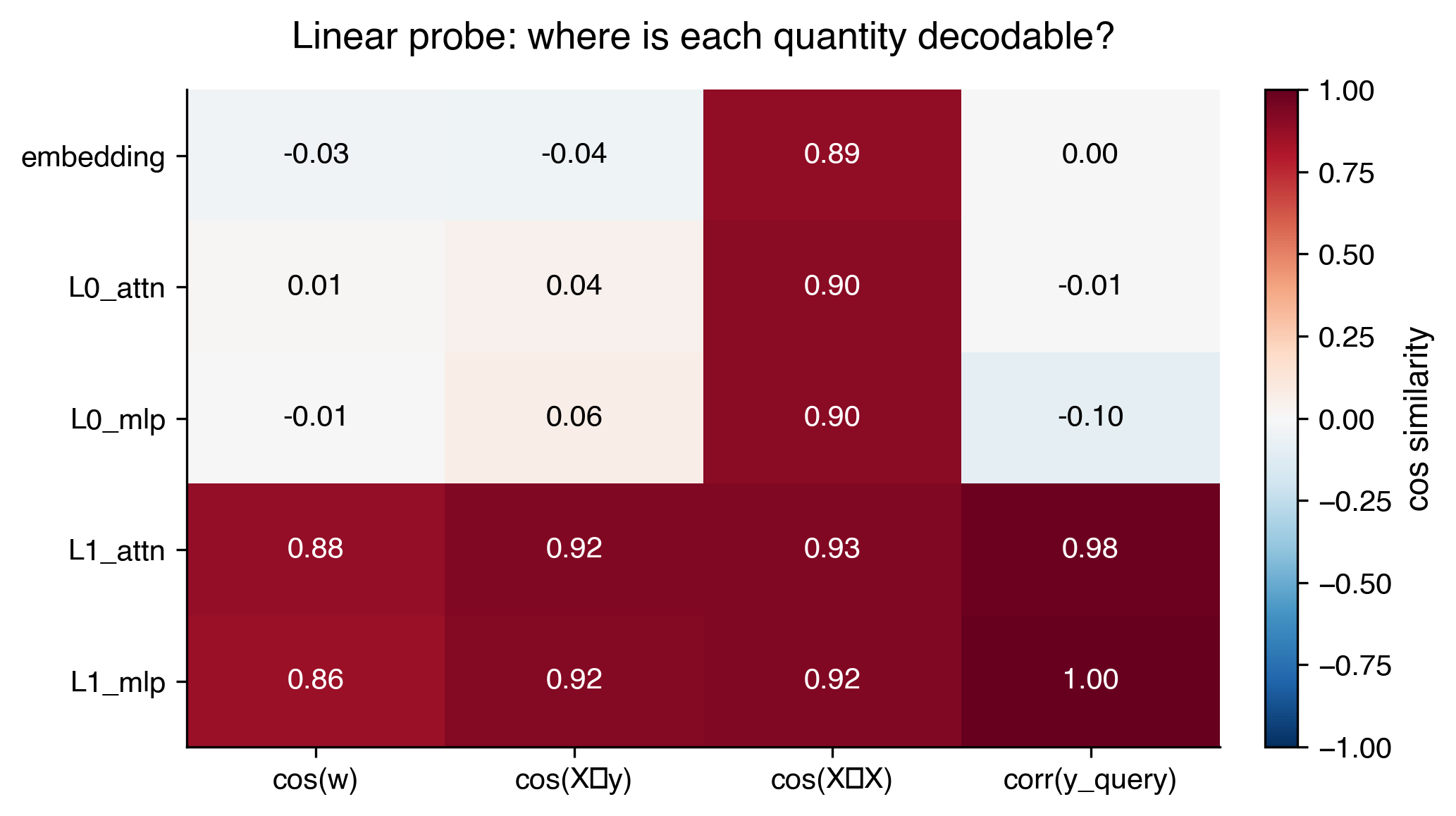
We see that $w$ and $X^Ty$ are readily accessible right after L1’s attention mechanism. What’s intriguing as well is their sharp emergence. They were barely linearly decodable after L0 MLP. This also suggests that L1 attention is doing something pretty useful. We will investigate this more carefully in a later section.
Activation patching
To further strengthen the claim that L1 attention is where a sharp transition occurs, I use a causal technique known as activation patching.
In activation patching, we take the current model (known as the recipient), patch in a different activation output (from a donor) in the residual stream, and we measure the impact on the final prediction.
In this case, both the recipient and donor receive different datasets in their prompt, but the same $x_q$. I perform activation patching at various sub-layers and see how the predictions change.
Results (n=200 donor→recipient pairs):
| Patch location | MSE to donor's answer | MSE to recipient's answer | Interpretation |
|---|---|---|---|
| embedding | 2.34 | 0.0009 | → Recipient |
| L0_attn | 2.25 | 0.075 | → Recipient |
| L0_mlp | 2.25 | 0.075 | → Recipient |
| L1_attn | 0.0009 | 2.35 | → Donor |
| L1_mlp | 0.0009 | 2.35 | → Donor |
We see results matching our linear probing results. A sharp transition occurs at L1 attention. Patching the $x_q$ residual stream before L1 attention has no effect on the final prediction (the model continues to output the recipient's answer). But patching at L1 attention or later flips the prediction entirely to the donor's answer. This tells us that the task-relevant computation is happening at L1 attention: the pre-L1 residual stream doesn't carry enough information to determine the answer, while the post-L1 residual stream fully determines it.
What is L0 doing?
With the understanding that L1 attention is clearly important, let's take a step back and understand the role of L0. L0 is definitely doing something, but it isn't apparent from the linear probing and activation patching experiments. When ablating any single L0 attention head (by ablation, I mean setting the output of the head to 0), the final MSE explodes by 46-801x across various seeds. Each L0 attention head is clearly contributing meaningfully to the final prediction.
What I found is a pattern similar in nature to what is described in Olsson et al. (2022)'s work on induction heads. Recall that the input prompt is of the form $[x_1, y_1, x_2, y_2, \ldots]$, where $x$-tokens sit at even positions and $y$-tokens at odd positions. Based on the attention patterns and V-projections in L0, I found that two heads are responsible for "mixing" each $x_k$ and $y_k$ pair together. Under the interpretation that attention performs a linear combination of V-projected residual streams, I found that each $y_k$ token attends almost entirely to the preceding $x_k$ token, with the effective V-projection being approximately the identity. The result is that each $x_k$ gets directly copied into the $y_k$ token's residual stream. What's also interesting is that each $(x_k, y_k)$ pair is mixed independently, with no cross-example interaction in L0. L0 is a per-example setup phase for the computation performed in L1 attention.
We know from linear probing that $X^\top y$ is linearly decodable in the L1 attention residual stream. It turns out that L1 attention alone cannot perform this computation without L0's help. To see why, $X^\top y = \sum_k x_k y_k$ requires multiplying each example $x_k$ by its corresponding label $y_k$, then summing across $k$. A single attention layer cannot produce this bilinear combination from separated $x$ and $y$ tokens, because doing so requires first pairing each $x_k$ with its $y_k$ (which L0 does via the copy mechanism above), before aggregating across $k$ (which L1 then does with a near-uniform attention pattern). This is why the 1L transformer from Part 0 failed to learn the task.
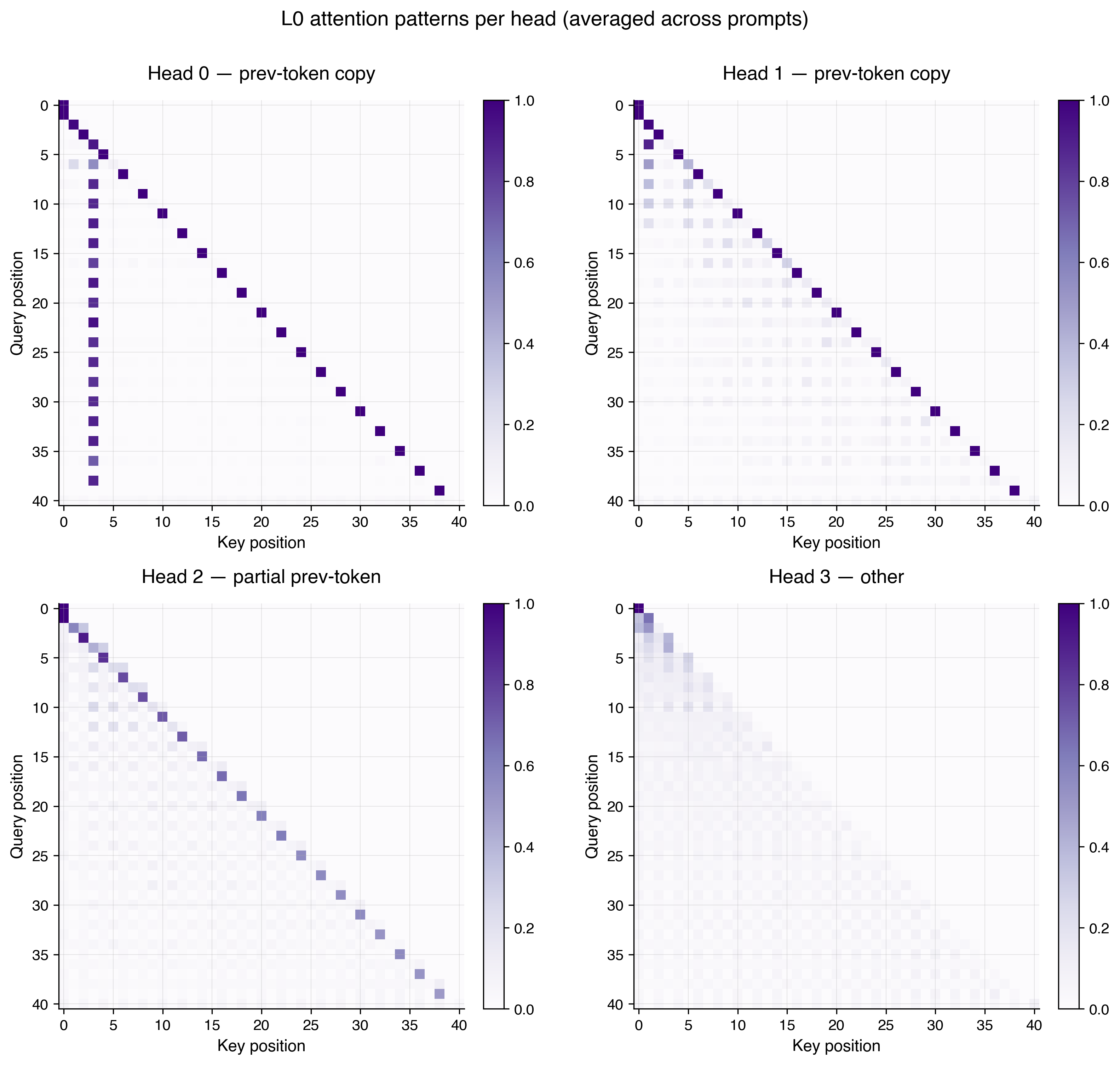
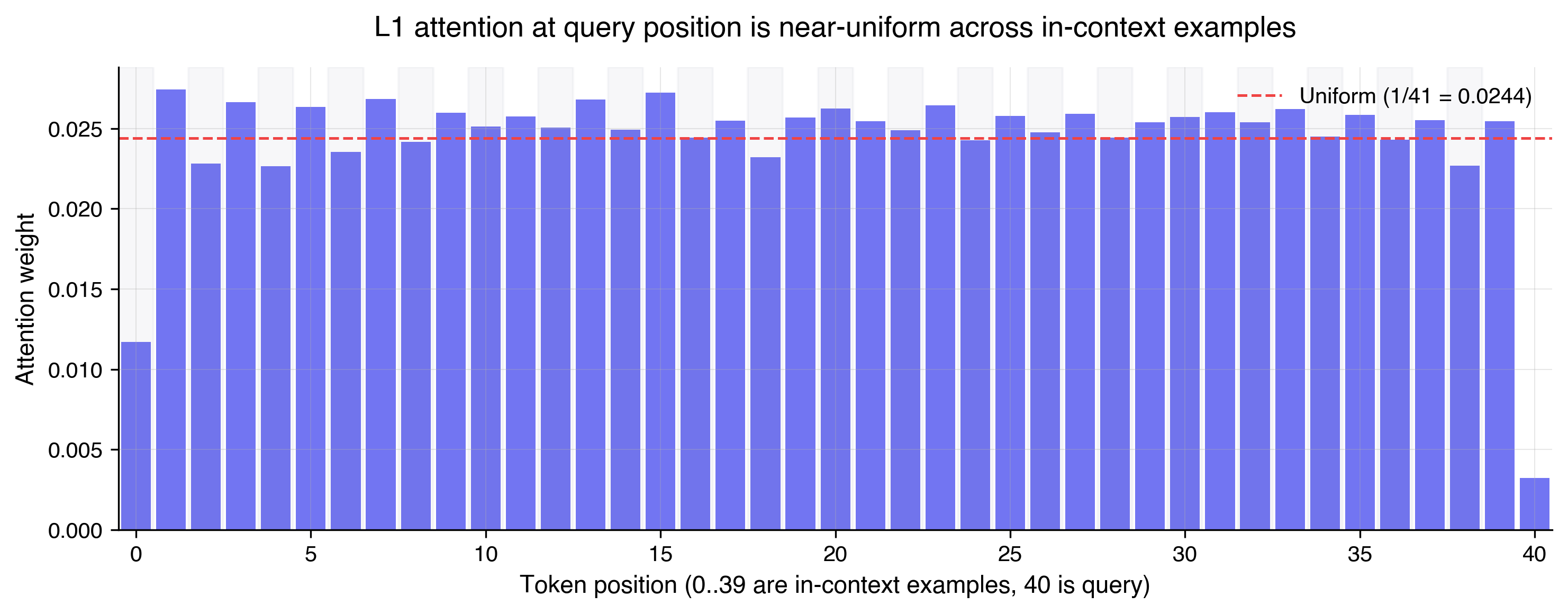
Examining L1 attention
Now that the role of L0 is better understood, we now revisit L1 attention, which is the heart of the model. Reusing our intuition that attention performs a linear combination of V-projected residual streams, we now expect L1 attention to be attending across all of the examples, which are now colocated, thanks to L0. The attention pattern in L1 I found is near-uniform, but not exactly uniform. One way to quantify "near-uniform" is to measure the entropy of the attention distribution. Entropy is maximized when weights are spread equally across all positions, and drops as the distribution concentrates on a few positions. L1 attention's entropy is about 98% of the maximum possible, meaning the weights are spread nearly equally across the 20 examples, but not perfectly so. Interestingly, when I replaced L1 attention with an exactly uniform attention pattern, the final MSE blows up by 1202x. It seems that the near-uniform pattern suggests that L1 attention values all of the examples roughly equally, while some computation is encoded in the slight deviations from uniform.
One interesting hypothesis I had in attempts to characterize L1 attention further is a "streaming computation" hypothesis. The idea here is that because we are using causal attention, perhaps L1 attention is building up the computation of $w$ incrementally across the examples. To test this, I linearly probed for incremental results of $w$, but did not find anything conclusive. It's an open question and future work to more accurately characterize L1 attention.
The role of L1 MLP
As a sanity check, like the previous sub-layers, I confirm that the L1 MLP actually matters in computing the final result. If I take L1_attn's output and apply the model's readout layer directly (skipping L1_mlp), the prediction correlates with $y_\text{true}$ at 0.986. But the MSE is 0.68, compared to the model's final MSE of 0.001. The direction is right; the scale is wrong.
So clearly the L1 MLP is doing something useful with respect to the final prediction. To characterize what it's doing, I fit a series of simple functions to approximate L1_mlp's input-output behavior, and measure how close each approximation gets to the model's actual final MSE.
| Correction | MSE vs $y_\text{true}$ |
|---|---|
| Scalar rescale ($\alpha \approx 0.56$) | 0.038 |
| Affine | 0.037 |
| Quadratic | 0.037 |
| Actual L1_mlp | 0.001 |
A simple scalar rescale gets MSE down from 0.68 to 0.038, capturing most of the correction L1 MLP applies. Adding affine or quadratic terms barely improves on this. But the actual L1 MLP achieves 0.001, nearly two orders of magnitude lower. This tells us that the dominant thing L1 mlp does is apply a scalar rescale, but the remaining gap to the model's final MSE requires a genuine nonlinearity that a low-order polynomial fit doesn't capture.
But beyond $X^\top y$ and $w$, we have yet to find evidence that the model is computing the inverse $(X^\top X + \lambda I)^{-1}$, which is the last significant computation in ridge regression. If we can find it, perhaps we can start to claim that our model has indeed rediscovered ridge regression and is performing it at an algorithmic level.
Despite extensive probing, I was not able to find evidence that the model computes this inverse in the general sense. This was surprising to me because the model seems to be computing partial components of ridge regression, like $X^\top y$, but it seems like the pressure during training forces the model to find a clever shortcut related to the distribution the data is sampled from, and it performs this shortcut at L1 MLP. I investigate this claim further in the next section.
Simplifying the inverse computation
Recall that $X$ are isotropic Gaussian inputs. Since each value is sampled from $\mathcal{N}(0, 1)$, you can expect that $\mathbb{E}[X^\top X] = n I$, where $n$ is the number of examples. This implies that: $$(X^\top X + \lambda I)^{-1} \approx (nI + \lambda I)^{-1} = \frac{1}{n + \lambda} I$$
Multiplying $X^\top y$ by this scalar value $\frac{1}{n + \lambda}$ is approximately the ridge solution, which is exactly the role of L1 MLP. Through this derivation, we have shown that the matrix inversion degenerates to scalar multiplication under the isotropic Gaussian data distribution.
A natural hypothesis now is that the model hasn't actually learned the final inverse computation, but instead found a shortcut rather than fully rediscovering ridge regression. We will pursue this hypothesis momentarily. The outcome that the model found a training distribution shortcut isn't all that surprising, but what is interesting is that the model appeared to at least partially compute ridge regression. A natural instinct is to try to train on more data (beyond just the isotropic Gaussian distribution), which is definitely worth doing, but I didn't do it for this blog. What I hypothesize is that the updated model would find new shortcuts of the distribution to exploit, and so we'd in some sense be moving goalposts. So instead, we opt to study the isotropic Gaussian distribution, which matches the experimental setup of prior work.
The model is a mimic, not a ridge regressor
We now confirm our suspicions above about our model finding a training distribution-specific shortcut in L1 MLP.
First, I confirm that when doing inference with datasets generated from anisotropic distributions, the model MSE explodes, while a real ridge regression still solves the problem successfully. We see that the scalar trick that the model learned cannot compensate for a real $X^\top X$ inverse. The eigenvalue structure of $X^\top X$ for anisotropic distributions is too different from the isotropic case that the model was trained on.
| Covariance | Condition # | Model MSE | Ridge MSE | Ratio |
|---|---|---|---|---|
| Identity | 1 | 0.0009 | 0.000001 | ~1000× |
| Diagonal anisotropic | 100 | 0.37 | 0.000003 | ~10⁵× |
| Strongly anisotropic | 10,000 | 30.7 | 0.00003 | ~10⁶× |
| Correlated | ~21 | 0.064 | 0.000001 | ~10⁵× |
Second, to further characterize the dependence on training distribution, I train a model from scratch where $x$ is sampled solely from a Rademacher distribution (each coordinate of $x$ is $+1$ or $-1$ with equal probability). This distribution still has the same $\mathbb{E}[X^\top X] = nI$ as Gaussian, but it is discrete rather than continuous. This is to test whether the model's mechanism depends on the inputs being continuous, and also to check whether the model might just memorize solutions. For our $d=5$, it's plausible that the model could memorize the $2^5 = 32$ possible $y$-outputs for each distinct $x$-input pattern, since the space of $x$-inputs is small.
What we find is that models trained on these different training distributions all successfully learn (as shown by low MSE on the training distribution). What is different is that for the Rademacher model, the linear decodability of $w$ is less stable across seeds. I hypothesize that the Rademacher-trained model has less consistent pressure to represent something resembling $w$, and instead lands on shortcuts more indicative of memorizing solutions. Not shown in this table, but when I evaluate a Rademacher-trained model on Gaussian inputs, the MSE explodes to 0.25 (~416×). This implies there is no real linear interpolation learned in the Rademacher-trained model. In fact, the training process has no motivation to learn this concept, since the discrete distribution rewards memorization just as well.
| $x$ distribution | cos($w$, L1_mlp) | MSE (training distribution) |
|---|---|---|
| Gaussian (original) | 0.88 | 0.001 |
| Uniform | 0.88 | 0.0003 |
| Laplace | 0.90 | 0.0009 |
| Rademacher (seed 42) | 0.53 | 0.0006 |
| Rademacher (seed 100) | 0.14 | 0.0013 |
| Rademacher (seed 200) | 0.69 | 0.0004 |
Taken together, these results show that our 2L model has not re-discovered ridge regression. It has found a shortcut that exploits the isotropy of the training distribution to collapse the matrix inverse into a simple scalar multiplication. This shortcut reproduces ridge's outputs on isotropic inputs, but breaks catastrophically the moment the input distribution changes. The model behaves like ridge, but it does not implement ridge on an algorithmic level.
What's interesting is that the model does develop partial representations of ridge. We found $X^\top y$ and $w$ as linearly decodable quantities in the residual stream, which are genuine components of ridge's computation. The model isn't doing something unrelated to ridge and getting lucky. It's doing part of ridge and then taking a distribution-specific shortcut for the part that's hard. We were able to pinpoint precisely where this substitution happens: at L1 MLP. With careful mechanistic analysis, we were able to find evidence of partial algorithmic implementation of ridge regression. The broader takeaway isn't just that the model fails OOD, but that it's important to go beyond behavioral matching when determining whether a model is actually implementing an algorithm.
Key Takeaways from Part 1
Mechanistic findings
- The 2L transformer behaviorally matches ridge regression but only partially implements it algorithmically. Linear probing reveals genuine ridge intermediates ($X^\top y$ and $w$) in the residual stream. The model is computing real components of ridge.
- The matrix inverse is not computed in the general sense. Instead, the model substitutes a scalar rescale at L1 MLP. Under isotropic Gaussian inputs, the matrix inverse is approximated as $\frac{1}{n+\lambda} I$. The L1 MLP applies a scalar rescale empirically, with a single-parameter approximation capturing 94% of its contribution to MSE reduction.
- The shortcut at L1 MLP is fragile. When inputs come from anisotropic distributions, the model's MSE explodes by 5–6 orders of magnitude relative to a real ridge regressor.
- L0 pairs each $x_k$ with $y_k$ via a per-example copy mechanism. This induction-head-style setup enables L1 attention to compute $X^\top y$, and explains why a 1L transformer cannot learn the task.
What's novel in this section
-
Mechanistic localization of the 2L shortcut at L1 MLP, with a specific functional form (scalar rescale). Behavioral analysis catches that the model fails OOD. Here, mechanistic analysis demonstrates that the model is running ridge partially, and substituting a shortcut for the inverse. We move beyond the general expectation that the model might fail under OOD, to localizing the specific component (L1 MLP) where the failure originates.
-
The analytical derivation tying the model's mechanism to its training distribution. We derived from first principles that under isotropic inputs, the matrix inverse in ridge regression degenerates to a scalar. We also showed empirically that the model implements a scalar rescale at L1 MLP. The contribution isn't just "the model exploits distributional structure" (which is unsurprising), but that the specific functional form of the exploitation is derivable from the data distribution alone.
Part 2: Scaling depth beyond the two-layer transformer
Note that this part is preliminary, and I report some initial findings I found most interesting or surprising.
We now investigate what happens when we scale beyond two layers. The basic quantitative motivation is straightforward: we saw in an earlier figure that MSE drops by orders of magnitude with depth (from approximately $10^{-2}$ at 2L to $10^{-5}$ at 8L, at 100k steps). It'll also be interesting to see what findings and intuitions from the 2L transformer experiments generalize.
Two natural intuitions frame what we might expect. From a computational perspective, more layers give the model room to perform the iterative inverse of $(X^\top X + \lambda I)$ directly, rather than taking the 2L shortcut. From a scaling laws perspective, scaling tends to improve model properties beyond just the training loss, including out-of-distribution behavior.
What I found contradicts both perspectives in an interesting way. The algorithm that the model discovers changes qualitatively between 3L and 4L, but the distributional failure mode from Part 1 persists through this internal mechanism change. Increasing depth changed how the model produced its predictions, but without changing which distributions its predictions are accurate on.
The primal to dual phase transition hypothesis
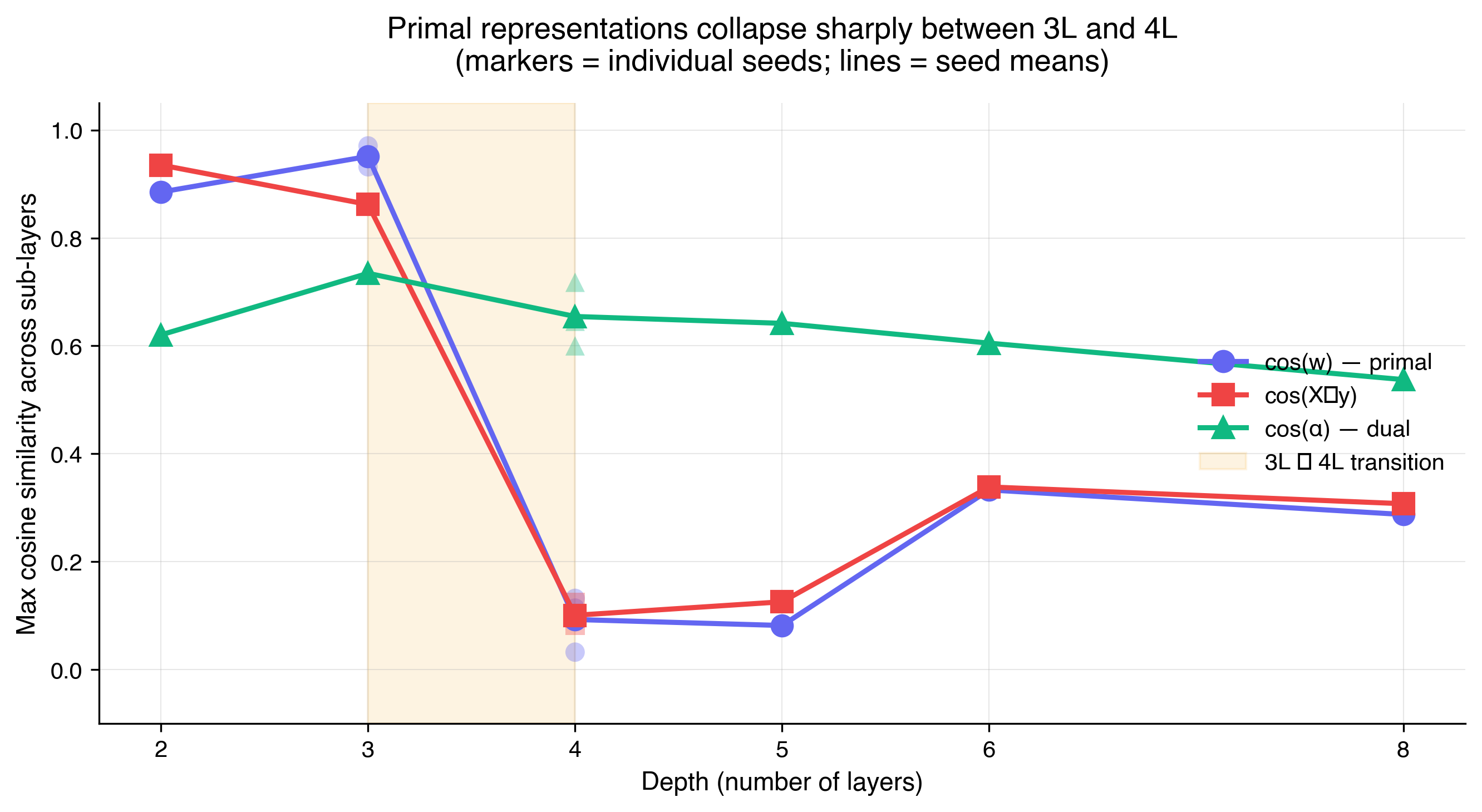
| Depth | cos($w$) | cos($X^\top y$) | cos($\alpha$) |
|---|---|---|---|
| 2L | 0.89 | 0.94 | 0.62 |
| 3L | 0.93, 0.97 | 0.86, 0.86 | 0.73, 0.74 |
| 4L | 0.11, 0.03, 0.13 | 0.12, 0.10, 0.08 | 0.60, 0.72, 0.65 |
| 5L | 0.08 | 0.13 | 0.64 |
| 6L | 0.33 | 0.34 | 0.61 |
| 8L | 0.29 | 0.31 | 0.54 |
2L, 5L, 6L, 8L: single seed (42). 3L: two seeds to confirm primal regime. 4L: three seeds to confirm the collapse replicates.
When we scale the depth of the model from 2L to 4L and beyond, the linear decodability of $w$ and $X^\top y$ collapses (from around $0.90$ to around $0.10$). This is strong evidence that the model has abandoned the primal formulation of linear regression. What's striking is how sharp and not gradual the transition is between 3L and 4L. A preliminary hypothesis is that the model has transitioned from the primal formulation to something dual-shaped.
The sudden loss of representation of $w$ is interesting and counter-intuitive. $w$ is a compressed summary of everything needed to reproduce the line underlying the data. One might expect that deeper models would converge toward finding this efficient representation, but deeper models steer away from it.
Let's briefly review the dual formulation. Rather than solving for $w$, the prediction is expressed as a weighted combination of the training labels:
$$\hat{y} = \sum_{i} \alpha_i(x_q) \cdot y_i$$
where $\alpha_i(x_q)$ are per-example coefficients that depend on the query, derived from kernel similarities $K(x_i, x_j)$ between training inputs and the query. For linear regression with a linear kernel, the primal and dual forms give identical predictions, but they are different algorithmically. Primal builds $w$ explicitly, dual never does. The dual is a more general form, and primal is a special case where the kernel happens to be linear. With depth, the model appears to move toward this more general form. While depth gives the model more capacity, it also more fundamentally gives the network access to algorithmic forms that shallower networks cannot reach or express. Whether the model prefers the more general form is an open question. My current hypothesis is that the model prefers the dual formulation due to the inductive bias of attention.
Probing for evidence of the dual
To test whether the 4L model is actually doing dual, I probed for $\alpha$, the per-example coefficient vector that a dual form would compute. If the $\alpha_i(x_q)$ values that a kernel-based dual would produce are linearly decodable from the 4L residual stream, this would be evidence that $\alpha$ is represented in the model. This is a necessary but not sufficient condition for the claim that the model is using the dual formulation.
The natural starting guess is the RBF kernel:
$$K(x_i, x_q) = \exp\left(-\frac{|x_i - x_q|^2}{2\sigma^2}\right)$$
For those unfamiliar with the theory, I can provide some background information. RBF is a similarity function based on distance. When used in kernel regression, RBF indicates that examples close to the query in input space matter more, examples far away matter less, with $\sigma$ as a hyperparameter controlling how fast similarity drops off. This is essentially what the standard softmax attention mechanism does (tokens with keys with higher dot product with the query matter more). The intuitive claim that softmax attention behaves like RBF-like functions has also been made more rigorous in recent work. Choromanski et al. (2021) showed that the softmax similarity function used inside attention can be rewritten as a Gaussian (RBF) similarity multiplied by some additional terms. Cheng et al. (2025) went further and argued that, in restricted settings, softmax attention performs a computation closely related to kernel regression, with RBF as the underlying kernel. All of this is to say, due to the similarities between RBF and softmax attention, testing for the RBF kernel is reasonable if we're trying to assess if our transformer model is doing kernel regression.
My linear probing results for $\alpha$ are suggestive but not conclusive. cos($\alpha$) is 0.62 at 2L and 0.60-0.72 across 4L seeds, which is slightly higher on average at 4L but with substantial seed-to-seed variance and overlap with the 2L baseline. Another complication is that, because $\alpha$ depends on $x_q$, the linear decoding of a single $\alpha$ vector from the residual stream is more of an approximation than a clean test. For these reasons, confirming the dual hypothesis remains as future work.
The contribution of this blog is the empirical observation of a sharp non-primal transition at 4L. Characterizing the kernel form precisely remains an open problem and is future work.
Depth vs Capacity
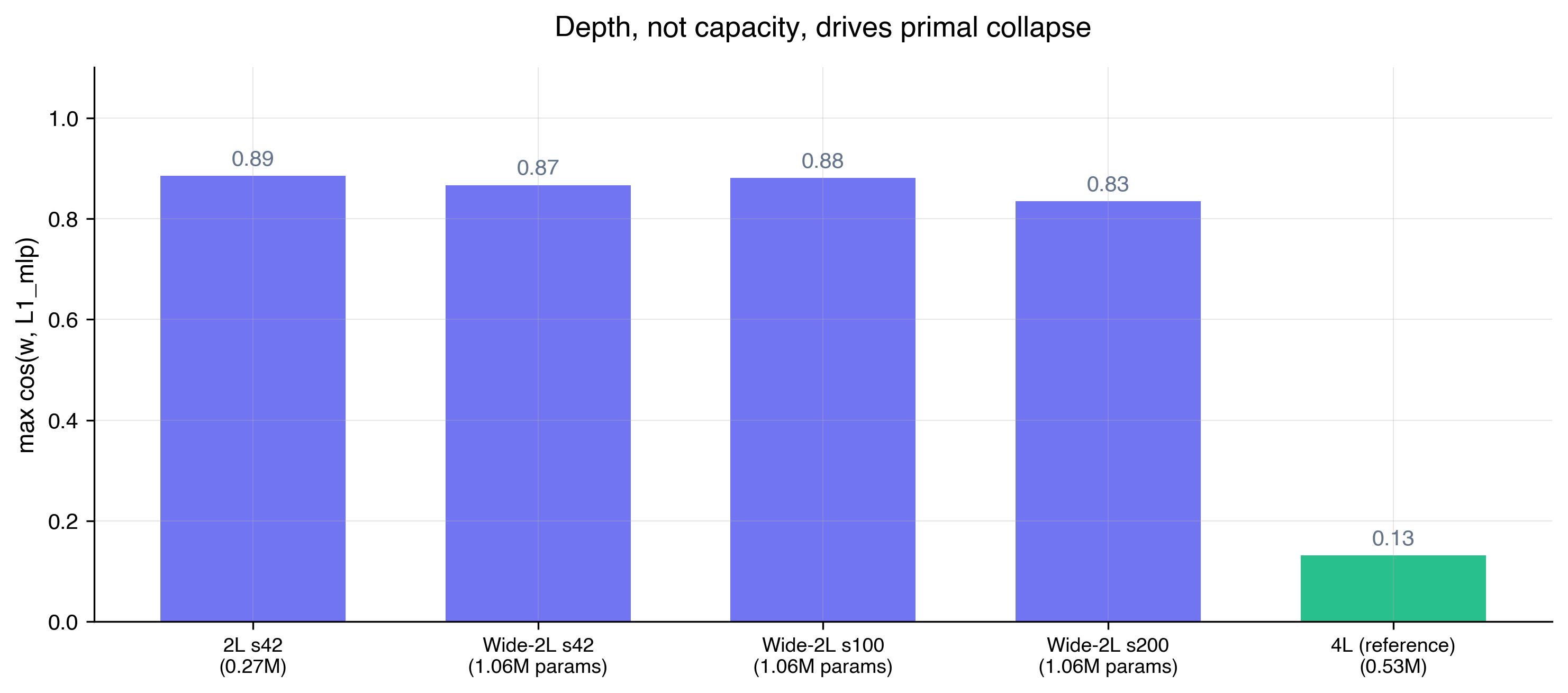
The most natural objection is that depth isn't necessarily what drives the algorithmic phase change. Perhaps it is also driven by capacity? To test this, I trained three additional 2L models with the hidden dimension widened to bring total parameter count to roughly 1M, around 4× the standard 2L (0.27M) and 2× the 4L (0.53M). The rest of the training setup was identical.
All three wide-2L seeds retained primal structure, with cos($w$) in the range $0.83$-$0.88$, comparable to the standard 2L (0.89) and far above any 4L seed (0.03-0.13). Adding more transformer layers unlocks the non-primal regime, not just adding more capacity.
$X^\top y$ as a strong primal vs dual probe
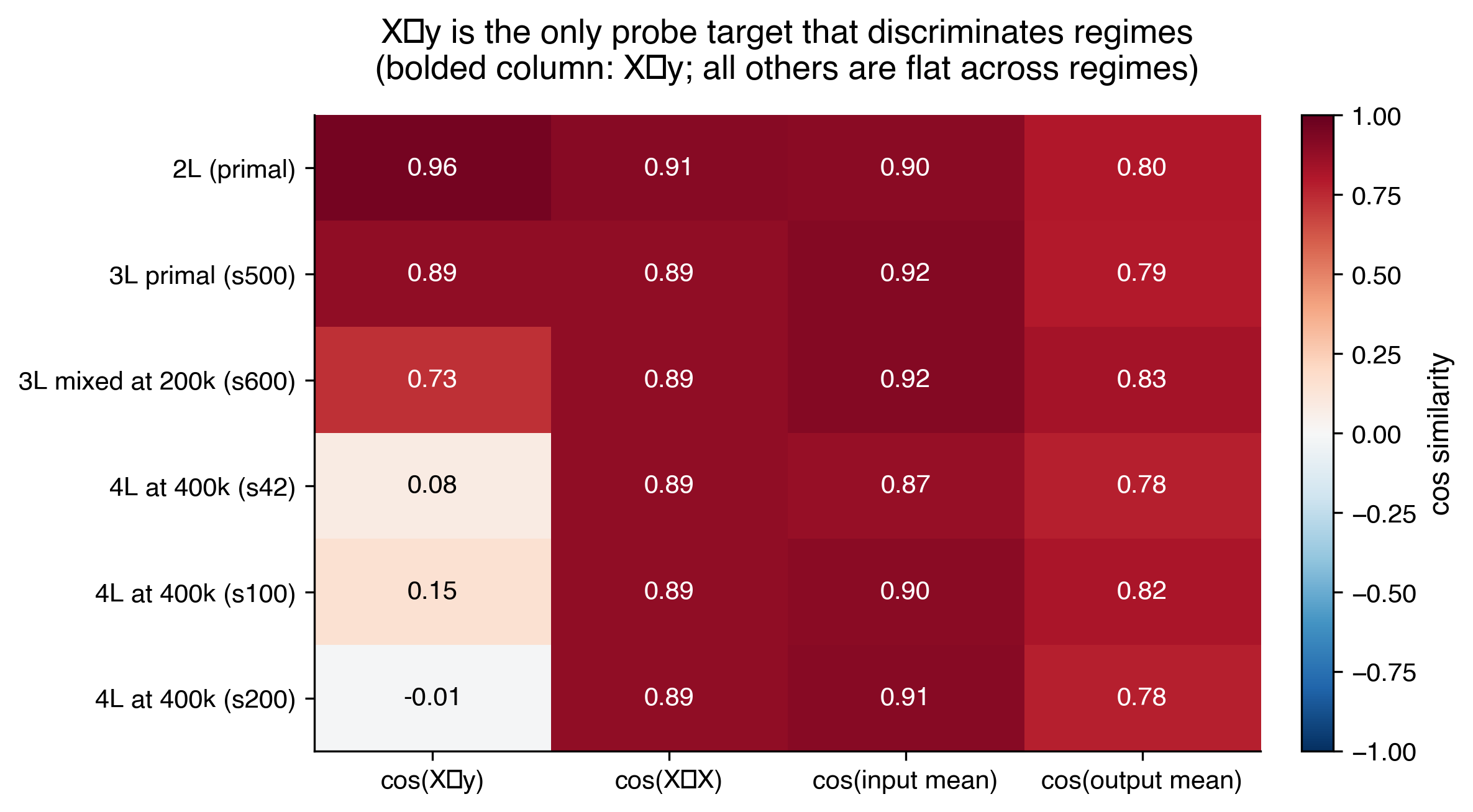
Throughout this work, I found $X^\top y$ to be a decent primal vs dual diagnostic. Intuitively, to compute $X^\top y$ the model has to take each example's $x_i$, multiply it by its corresponding label $y_i$, and sum across all 20 examples, which the model has to build up from scratch by combining information across examples. It's unlikely the model would build up this specific bilinear quantity as a byproduct of unrelated computation. So if $X^\top y$ is decodable from the residual stream, it's good evidence the model actually computed it as part of its algorithm.
The steep drop in cos($X^\top y$) between 3L (0.86) and 4L (0.08-0.12) coincides with the drop in cos($w$), which essentially confirms that the model is no longer computing primal.
Extended training resolves 3L
My initial analysis of the phase transition between 2L, 3L, and 4L was messy and inconclusive at first. I was training to 200k steps, which was the standard across ICL papers using this setup. However, at 200k steps, some 3L seeds looked partial or mixed. One seed showed cos($w$) ≈ 0.04, closer to 4L than 3L. This initially suggested 3L might be an unstable transition regime where primal and other formulations were both reachable.
When I extended training to 400k and 800k steps, the anomalous 3L seeds resolved to clean primal (cos($w$) = 0.99, cos($X^\top y$) = 0.94). At 200k steps, the model was in a transient state. This suggests that the boundary between 3L and 4L is sharp at convergence, where 3L converges to primal and 4L converges to non-primal, with no ambiguous regime in between, at least within the depths and seeds I tested.
On a methodological level, this suggests that mech interp conclusions drawn at standard training budgets can sometimes reflect transitional states rather than what the model will actually converge to.
4L still contains a distributional shortcut
I also evaluated the 4L model on the training distribution (isotropic Gaussian) and on anisotropic out-of-distribution shifts and compared their predictions to a true ridge regressor. The table below shows whether each model produces ridge-like predictions on each distribution, compared side-by-side with 2L's outcomes.
| Distribution | 2L | 4L (mean across seeds) |
|---|---|---|
| Training distribution (isotropic Gaussian) | Roughly matches ridge | Closely matches ridge |
| Anisotropic | Fails | Fails |
| Strong anisotropic | Fails | Fails |
| Correlated | Fails | Fails |
On the training distribution, both models track ridge regression, with 4L outperforming 2L (13× and 1100× ridge's error, respectively), indicating that depth genuinely helps in-distribution.
But on the anisotropic distributions, both models fail, with errors that are tens of thousands to tens of millions of times worse than ridge. Depth changes the magnitude slightly but not the qualitative outcome.
Depth dramatically improves in-distribution accuracy, but doesn't enable the model to escape OOD failures. This suggests that a training-distribution shortcut also exists in deeper models, and characterizing it precisely is future work.
Future Work
Several threads in this analysis are unresolved, and I plan to pursue them further in subsequent blog posts.
Confirming whether 4L+ implements the dual. I have evidence that 4L and beyond have abandoned the primal formulation, but evidence that they implement the dual is suggestive rather than conclusive. Better diagnostics, possibly designed to detect kernel structure directly, would help resolve this. If it turns out that a transformer trained on linear regression is converging to a kernel regression solution rather than the obvious primal solution, it's evidence that attention's inductive bias steers optimization away from the most direct algorithmic form and toward forms that match the architecture's bias. Confirming this may have implications for what algorithms transformers actually prefer when given freedom to choose.
Scaling beyond synthetic linear regression. This blog studies a standard clean task with a known optimal solution. Whether the findings here appear in other ICL settings (classification, language modeling) is still open. If we can show that the same patterns hold on more general tasks, then the methodological takeaways here can become tools we can apply to frontier models.
Scaling to larger transformers. The largest model studied here is 8L with $d_\text{model} = 128$. Whether the algorithmic phase transition and OOD-shortcut persistence patterns hold at frontier scales is open.
Predicting shortcut form from training distribution. Part 1 showed that we can derive the form of the 2L model's shortcut from the isotropy of the input distribution. A natural extension is to test whether this framework generalizes. Given a new training distribution with different structure, can we predict what shortcut form a trained model will adopt before training it? This is interesting because it implies that instead of studying a model's shortcuts after the fact, we may be able to anticipate shortcuts from the training data. This is useful for catching generalization failures earlier and for designing training distributions that don't admit easy shortcuts.